

by drmunozcl
Share
Por drmunozcl
Compartir
En ciberseguridad, «fallar con seguridad» no es un eslogan; es un principio operativo. Significa que, cuando algo sale mal, el sistema adopta por defecto el estado más seguro posible. Si un servicio crítico cae, si una dependencia no responde o si un componente se degrada, «fallar con seguridad» garantiza que la confidencialidad, la integridad y el control de acceso prevalezcan sobre la disponibilidad.
Por qué importa fallar con seguridad
Los sistemas fallan. Redes se particionan, certificados expiran, cachés se corrompen y proveedores SaaS tienen incidentes. El riesgo no está solo en la caída, sino en cómo responde tu arquitectura al fallo. Si el diseño prioriza la continuidad a cualquier costo, abres puertas. Cuando no se aplica «fallar con seguridad», un error de autenticación puede convertirse en acceso anónimo, un timeout del WAF en tráfico sin inspección y un fallo del gestor de claves en datos en claro.
Conviene distinguir: fail-safe protege a las personas cuando algo falla (por ejemplo, un ascensor que se detiene en lugar de caer). Fail-secure («fallar con seguridad») prioriza que los datos y los accesos se mantengan protegidos, incluso si eso interrumpe el servicio. En seguridad corporativa, negar por defecto y exigir verificación antes de permitir es la ruta más sana.
El principio en la práctica: patrones para fallar con seguridad
Implementar «fallar con seguridad» exige decisiones concretas en cada capa. Piensa en compuertas cortafuego que se cierran cuando detectan humo: el objetivo no es seguir operando a toda costa, sino contener el riesgo.
Acceso y autenticación
- Negar por defecto (default deny) en IAM, firewalls y permisos de API.
- Si el validador de tokens o el IdP no responden, deniega el inicio de sesión. No aceptes tokens sin verificar firma ni expiración.
- MFA: si el proveedor de OTP está caído, exige otro factor equivalente (push, FIDO2) o bloquea temporalmente; no rebajes a single-factor.
- Revocación: ante duda, trata el token/certificado como revocado.
Redes y perímetros
- Firewalls y SG deben tener políticas drop por defecto para ingress y egress.
- API Gateway: si el motor de políticas falla, responde 403 en lugar de enrutar ciegamente.
- TLS: ante errores de handshake, niega la conexión; aplica OCSP stapling para validar revocación sin introducir soft-fails.
- WAF/IPS: preferir fail-closed cuando protegen activos críticos; aislar para no convertirlos en punto único de caída.
Datos y cifrado
- Si KMS/HSM no está disponible, bloquea lecturas/escrituras que requieran cifrado o firmas; no almacenes en claro.
- Rotación de claves: si falla, detén despliegues que dependan de esa rotación.
- Integridad: si checksums o firmas no validan, descarta el artefacto y alerta.
- Logs: escribe en modo append-only y con sellado criptográfico; si el backend de logs falla, cachea en disco cifrado y autoenvía al restablecer.
Aplicaciones y microservicios
- Circuit breakers: cuando un servicio cae, corta y devuelve un error seguro; no devuelvas datos cacheados sin validación.
- Feature flags por defecto en «off»; el fallo del servicio de flags no debe habilitar funciones no auditadas.
- Configuración: valores seguros por defecto, sin fallback a credenciales embedidas.
- Manejo de errores: mensajes genéricos para el cliente, diagnóstico detallado solo en logs internos.
Usuario final y experiencia
- Si debes denegar, hazlo con claridad y ofrece un camino de recuperación (soporte, reintento, modo lectura sin datos sensibles).
- Modos offline: limitar a capacidades de bajo riesgo; nunca elevar privilegios por ausencia de conectividad.
Errores comunes que rompen «fallar con seguridad»
- Fallbacks que omiten validaciones criptográficas para «mejorar la experiencia».
- Valores por defecto inseguros en librerías o contenedores.
- Dependencias críticas sin aislamiento ni backpressure.
- Mensajes de error verbosos que filtran secretos o topología.
Conclusión: diseña hoy tu próximo fallo
La pregunta no es si tu plataforma fallará, sino cómo. Si decides «fallar con seguridad», conviertes eventos inevitables en incidentes contenidos. Empieza por tres acciones: aplica default deny donde aún no existe, define el estado seguro de cada componente y automatiza pruebas de caos que validen el comportamiento. En Infoprotección podemos ayudarte a auditar tus controles, priorizar cambios y entrenar a tu equipo para que la próxima caída te encuentre preparado.
MANTENTE INFORMADO
Suscríbete a nuestro newsletter gratuito.

La inteligencia artificial ya no es solo una herramienta para empresas y desarrolladores. En 2026, investigadores de ciberseguridad han detectado una nueva generación de amenazas que integran modelos de lenguaje (LLMs) directamente en su funcionamiento. Dos nombres están marcando tendencia en el mundo de la seguridad informática: PromptFlux y QuietVault. Estos malwares representan un cambio

La conversación dejó de ser “si me van a atacar” y pasó a “cuándo, cómo y qué tan caro me va a salir”. Hoy, los costos de ciberseguridad en empresas ya no se miden solo en tecnología, sino en interrupciones operativas, sanciones regulatorias y pérdida de confianza del mercado. A modo de referencia reciente, un

La ciberseguridad ya no es una preocupación “a futuro”. Las amenazas que dominarán 2026 ya están ocurriendo hoy, afectando a empresas de todos los tamaños, sectores y regiones. Ataques más rápidos, automatizados y difíciles de detectar están redefiniendo la forma en que las organizaciones deben proteger su información. En este escenario, entender qué está cambiando
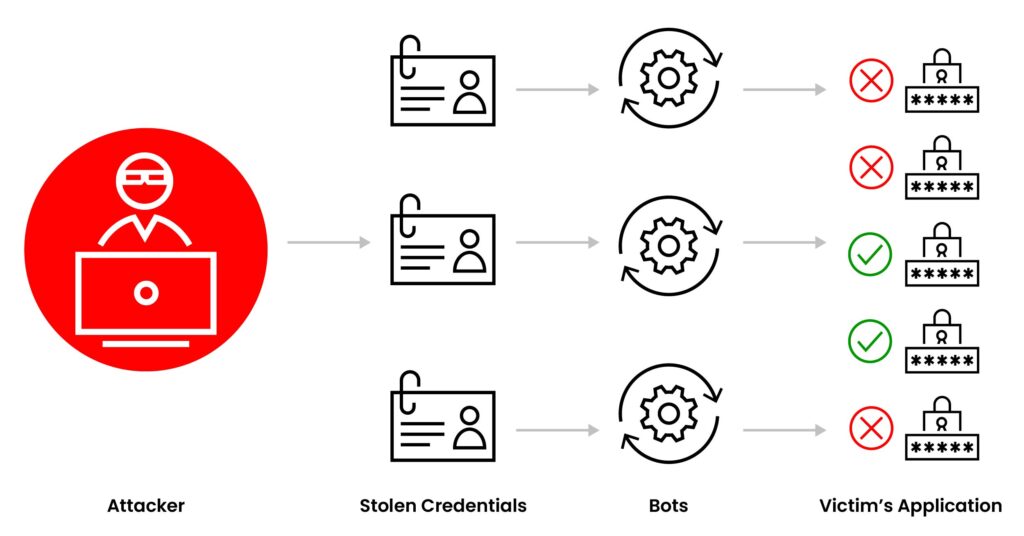
Te preguntas «¿Qué es Credential Stuffing?» Es un ataque automatizado donde delincuentes prueban, a gran escala, combinaciones de usuario y contraseña filtradas en otros servicios. Si un usuario reutiliza credenciales, el atacante accede sin necesidad de hackear el sistema. Spoiler: no son hackers con capucha adivinando contraseñas una por una, son bots probando miles por

