

by drmunozcl
Share
Por drmunozcl
Compartir
Cuando ocurre un incidente, cada minuto cuenta. Un manual de respuesta a incidentes convierte el caos en un proceso claro, repetible y medible. Sin él, incluso equipos expertos improvisan, pierden tiempo valioso y arriesgan datos, reputación y continuidad de negocio.
Qué es un manual de respuesta a incidentes y por qué importa
Un manual de respuesta a incidentes es la guía operativa que especifica cómo tu organización detecta, clasifica, contiene, erradica y aprende de un incidente de seguridad. No es un documento estático; es un sistema vivo de decisiones, flujos y responsabilidades.
Sin un manual de respuesta a incidentes, las acciones se vuelven reactivas. Los equipos discuten prioridades, las evidencias se contaminan y la comunicación se fragmenta. Es como entrar a un quirófano sin protocolo: el talento no sustituye a la coordinación.
Un buen manual de respuesta a incidentes alinea tecnología, procesos y personas. Reduce la incertidumbre, acorta tiempos de contención y mejora la calidad forense. También facilita auditorías, seguros cibernéticos y cumplimiento regulatorio.
Estructura esencial de un manual de respuesta a incidentes
La forma sigue a la función. Un manual de respuesta a incidentes efectivo suele incluir:
1) Propósito, alcance y definiciones
- Objetivo del documento, sistemas y ubicaciones cubiertas, supuestos y exclusiones.
- Glosario operativo para evitar ambigüedades (p. ej., «incidente», «evento», «alarma»).
2) Gobernanza y RACI
- Roles, responsables y suplentes (CISO, IR Lead, SOC, Legal, PR, HR, TI, Proveedores).
- Matriz RACI por fase para que nadie duplique esfuerzos ni omita pasos.
3) Clasificación de severidad y criterios de activación
- Niveles de severidad (SEV-1 a SEV-4) con umbrales objetivos: alcance, criticidad, impacto en negocio.
- Triggers claros: cuándo se activa el equipo ampliado y cuándo se escala a dirección.
4) Flujo de respuesta en 6 fases
- Preparación, Detección/Análisis, Contención, Erradicación, Recuperación y Lecciones aprendidas.
- Para cada fase: entrada, actividades, decisiones, salidas y responsables.
5) Playbooks específicos
- Guías paso a paso por tipo de incidente: ransomware, phishing con compromiso de credenciales, exfiltración de datos, web shell, DDoS, insider threat.
- Árboles de decisión y checklists accionables.
6) Comunicaciones internas y externas
- Plantillas de notificación y briefing por audiencia (dirección, equipos técnicos, legal, PR).
- Canales y ventanas de comunicación; reglas de confidencialidad y coordinación con terceros.
7) Gestión de evidencias y forense
- Procedimientos de cadena de custodia, timestamping, imágenes forenses, aislamiento y preservación de logs.
- Estándares mínimos: sincronización NTP, retención de registros, hash de integridad.
8) Herramientas, accesos y runbooks
- Inventario de herramientas (EDR, SIEM, SOAR, IR kits, scripts) con propietarios y accesos de emergencia.
- Runbooks de contención rápida: reglas EDR, bloqueos en firewall/IDP, rotación de credenciales.
9) Métricas y mejora continua
- KPIs/KRIs: MTTD, MTTR, tiempo a contención, ratio de falsos positivos, cumplimiento de SLA.
- Proceso de postmortem sin culpas, acciones correctivas y ciclo de versión del manual.
Ejemplo práctico: ransomware en servidor de archivos
Imagina un servidor de archivos con comportamiento anómalo, extensiones cifradas y notas de rescate.
- Detección/Análisis: El SOC correlaciona alertas EDR y anomalías SMB. Clasifica como SEV-2 por impacto en datos compartidos.
- Contención: Desconectas el servidor de la red, suspendes cuentas comprometidas y bloqueas IoCs en EDR/Firewall.
- Erradicación: El equipo limpia persistencias, elimina tareas programadas maliciosas y valida que no existan backdoors.
- Recuperación: Restauras desde backups verificados, patching, hardening y rotación de claves. Validas integridad con hashes de referencia.
- Lecciones aprendidas: Actualizas el playbook de ransomware, ajustas reglas de detección y mejoras la segmentación.
Sin un manual de respuesta a incidentes, cada paso anterior se lentifica y se llena de suposiciones. Con él, el equipo ejecuta como un drill de bomberos.
Plantilla recomendada y recursos
No necesitas empezar desde cero. Revisa la guía oficial del gobierno australiano, una referencia clara y práctica para estructurar tu manual de respuesta a incidentes: ACSC Cyber Incident Response Plan Guidance.
¿Qué puedes extraer de ese recurso?
- Secciones modulares que puedes adaptar a tu contexto.
- Ejemplos de criterios de severidad y flujos de decisión.
- Buenas prácticas de comunicación y coordinación interáreas.
Conclusión
Un manual de respuesta a incidentes bien diseñado no es un archivo más: es tu seguro operativo cuando todo arde. Te da claridad bajo presión, reduce impacto y acelera la recuperación. Refuérzalo con la guía del ACSC y conviértelo en hábito mediante simulacros.
Si necesitas apoyo para evaluar, estructurar o probar tu manual de respuesta a incidentes, en Infoprotección podemos ayudarte a aterrizarlo con precisión y velocidad.
MANTENTE INFORMADO
Suscríbete a nuestro newsletter gratuito.

La inteligencia artificial ya no es solo una herramienta para empresas y desarrolladores. En 2026, investigadores de ciberseguridad han detectado una nueva generación de amenazas que integran modelos de lenguaje (LLMs) directamente en su funcionamiento. Dos nombres están marcando tendencia en el mundo de la seguridad informática: PromptFlux y QuietVault. Estos malwares representan un cambio

La conversación dejó de ser “si me van a atacar” y pasó a “cuándo, cómo y qué tan caro me va a salir”. Hoy, los costos de ciberseguridad en empresas ya no se miden solo en tecnología, sino en interrupciones operativas, sanciones regulatorias y pérdida de confianza del mercado. A modo de referencia reciente, un

La ciberseguridad ya no es una preocupación “a futuro”. Las amenazas que dominarán 2026 ya están ocurriendo hoy, afectando a empresas de todos los tamaños, sectores y regiones. Ataques más rápidos, automatizados y difíciles de detectar están redefiniendo la forma en que las organizaciones deben proteger su información. En este escenario, entender qué está cambiando
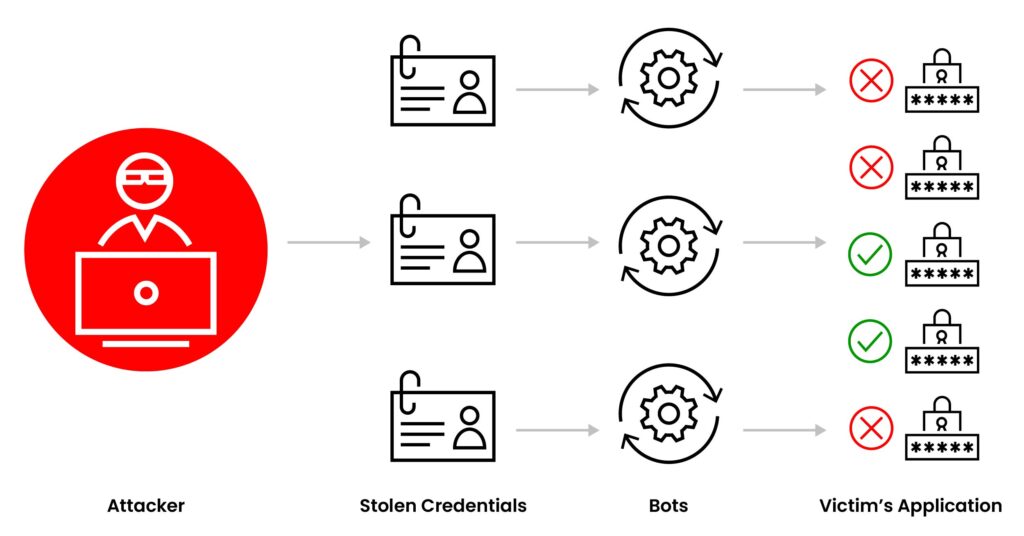
Te preguntas «¿Qué es Credential Stuffing?» Es un ataque automatizado donde delincuentes prueban, a gran escala, combinaciones de usuario y contraseña filtradas en otros servicios. Si un usuario reutiliza credenciales, el atacante accede sin necesidad de hackear el sistema. Spoiler: no son hackers con capucha adivinando contraseñas una por una, son bots probando miles por

