

by drmunozcl
Share
Por drmunozcl
Compartir
La superficie de ataque crece con cada nuevo servicio expuesto, dispositivo conectado y nube integrada. Una red plana, configuraciones por defecto, puertos abiertos sin control o protocolos obsoletos convierten cualquier incidente menor en un movimiento lateral devastador. El resultado es predecible: ransomware con alto tiempo de inactividad, exfiltración de datos y costos de recuperación que superan el presupuesto anual de TI. En Infoprotección proponemos un enfoque metódico de endurecimiento de red para reducir riesgos de forma medible, sin frenar el negocio.
¿Por qué el endurecimiento de red importa hoy?
La mayoría de intrusiones significativas se apoyan en errores básicos: credenciales por defecto en equipos de red, RDP/VPN mal configuradas, reglas de firewall permisivas, ausencia de segmentación o falta de registros útiles para investigar. El endurecimiento de red (network security hardening) ordena las prioridades: minimizar superficie de ataque, autenticar de forma robusta, segmentar para contener, observar para detectar y responder. Implementado por fases, reduce la probabilidad de intrusión y limita el impacto si ocurre.
Prácticas de endurecimiento de red: lista priorizada
A continuación, un conjunto de prácticas que todo analista de seguridad debería aplicar en una empresa moderna. Están organizadas para obtener victorias rápidas y construir controles duraderos.
Inventario y clasificación de activos
Descubre y etiqueta switches, routers, firewalls, controladores Wi‑Fi, balanceadores, dispositivos IoT/OT y enlaces híbridos (SD‑WAN, VPN, nubes). Usa escaneo activo más telemetría (ARP, LLDP, SNMPv3) y concílialo en CMDB. Sin inventario, no hay control ni auditoría.
Baselines de configuración seguras
Define plantillas con líneas mínimas: banners legales, NTP, logging remoto, deshabilitar servicios no usados, timeouts de sesión, control de banners y MOTD, password policies y saltos administrativos separados. Versiona las plantillas y aplícalas de forma automatizada (Ansible, NCM).
AAA centralizado y trazabilidad
Implementa autenticación y autorización centralizadas (TACACS+/RADIUS) con cuentas nominales, MFA para accesos privilegiados y perfiles de rol. Prohíbe cuentas compartidas y registra cada comando. Esto reduce abuso interno y acelera forense.
Protocolos y criptografía robustos
Elimina Telnet, HTTP y SNMPv1/v2c; usa SSHv2, HTTPS/TLS 1.2+ y SNMPv3 con cifrado y autenticación. Cierra puertos de gestión en data plane y habilita un plano de administración fuera de banda (OOB) donde sea posible.
Segmentación y microsegmentación
Separa usuarios, servidores, aplicaciones críticas y entornos (prod/dev) con VLANs, VRFs y ACLs/filtros de capa 4–7. Aplica un modelo «deny by default» y permite solo flujos necesarios. Complementa con microsegmentación (host-based o SDN) para frenar el movimiento lateral.
Control de acceso a la red (802.1X/NAC)
Exige autenticación basada en certificados para cableado y Wi‑Fi (EAP‑TLS). Usa NAC para aplicar políticas de postura (parches, EDR activo) y colocar dispositivos en VLANs adecuadas. Aísla invitados, BYOD e IoT con políticas restringidas.
Higiene de firewall y control de salida
Revisa reglas con caducidad, justificación y propietario. Implementa filtrado de egress para bloquear canales de C2 y exfiltración (DNS/TCP/UDP anómalos). Activa inspección de aplicaciones donde proceda y registra «permit/deny» en SIEM.
Seguridad de capa 2
Habilita DHCP Snooping, Dynamic ARP Inspection y Port Security. Protege spanning‑tree con BPDU Guard y Root Guard. Activa storm control y desactiva puertos no usados. Estas medidas detienen suplantación y ataques locales en la LAN.
Wi‑Fi corporativo endurecido
Usa WPA3‑Enterprise con PMF (802.11w), desactiva WPS y oculta SSIDs innecesarios. Separa SSID de invitados, aplica límites de tasa y segmentación. Asegura el roaming con perfiles gestionados y certificados.
Registro y observabilidad
Envía Syslog a un colector central con integridad, captura NetFlow/IPFIX y activa NDR/IDS donde sea útil. Sincroniza tiempo con NTP seguro. Establece retención por criticidad y crea alertas accionables (autenticaciones fallidas, cambios de config, flujos inusuales).
Gestión de vulnerabilidades y parches
Monitorea avisos del fabricante, evalúa CVSS y exposición real y aplica parches de forma programada. Donde no sea posible, mitiga con ACLs y segmentación. Automatiza el control de versión y la comprobación post‑cambio.
Resiliencia y copias de seguridad
Realiza backups cifrados de configuraciones, prueba restauraciones y conserva «golden configs». Implementa redundancia de plano de control/datos (HSRP/VRRP, ECMP) según criticidad. Documenta RTO/RPO de servicios de red.
Protección DNS
Usa resolutores internos con filtrado de dominios maliciosos, DNSSEC donde aplique y políticas para bloquear tunneling. Registra consultas para detección temprana de C2 y typosquatting.
Acceso remoto seguro (VPN/ZTNA)
Obliga MFA, evalúa el split tunneling según riesgo y limita el acceso a aplicaciones necesarias. Considera ZTNA para sustituir VPN amplias con acceso granular y contexto de dispositivo.
Errores frecuentes a evitar
- Posponer la segmentación por «compleja». La segmentación es el control con mayor retorno en contención de incidentes.
- Tratar el NAC como proyecto de «todo o nada». Empieza en monitor mode, ajusta y luego aplica políticas.
- Exceso de confianza en VPN sin MFA y sin restricción por aplicación. Menos es más; reduce el alcance.
- Logs que no llegan al SIEM o sin normalización. Sin registros accionables, la detección llega tarde.
- No probar restauraciones de configuración. Un backup no verificado es una apuesta.
Conclusión
El endurecimiento de red no es un check‑list de una sola vez; es un ciclo continuo de reducción de superficie de ataque, autenticación fuerte, segmentación, observabilidad y respuesta. Si comienzas por inventario, baselines y AAA, y progresas hacia segmentación, NAC y telemetría, disminuirás de forma tangible la probabilidad de intrusión y el impacto de cualquier incidente. Con disciplina operativa y métricas, tu red soportará el negocio con seguridad y previsibilidad.
MANTENTE INFORMADO
Suscríbete a nuestro newsletter gratuito.

La inteligencia artificial ya no es solo una herramienta para empresas y desarrolladores. En 2026, investigadores de ciberseguridad han detectado una nueva generación de amenazas que integran modelos de lenguaje (LLMs) directamente en su funcionamiento. Dos nombres están marcando tendencia en el mundo de la seguridad informática: PromptFlux y QuietVault. Estos malwares representan un cambio

La conversación dejó de ser “si me van a atacar” y pasó a “cuándo, cómo y qué tan caro me va a salir”. Hoy, los costos de ciberseguridad en empresas ya no se miden solo en tecnología, sino en interrupciones operativas, sanciones regulatorias y pérdida de confianza del mercado. A modo de referencia reciente, un

La ciberseguridad ya no es una preocupación “a futuro”. Las amenazas que dominarán 2026 ya están ocurriendo hoy, afectando a empresas de todos los tamaños, sectores y regiones. Ataques más rápidos, automatizados y difíciles de detectar están redefiniendo la forma en que las organizaciones deben proteger su información. En este escenario, entender qué está cambiando
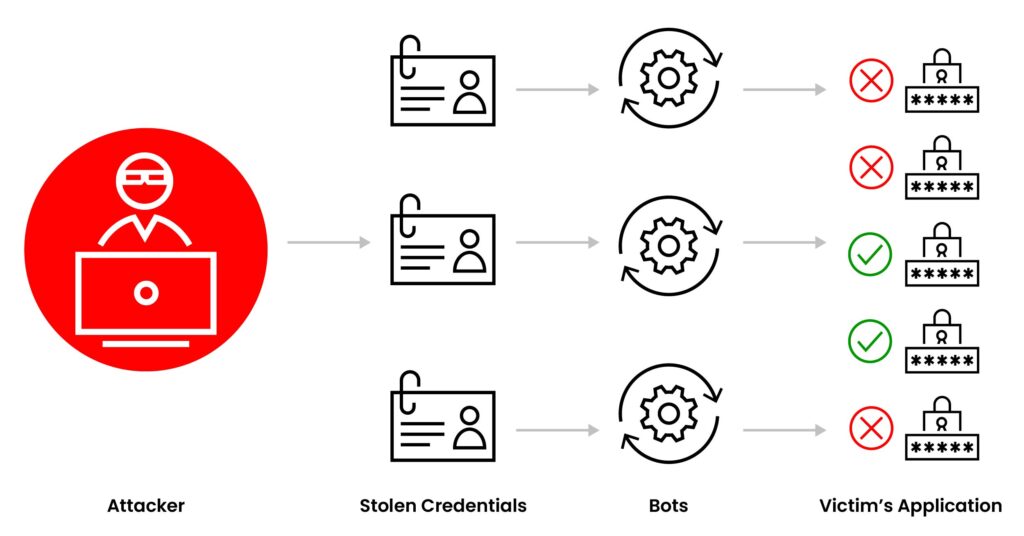
Te preguntas «¿Qué es Credential Stuffing?» Es un ataque automatizado donde delincuentes prueban, a gran escala, combinaciones de usuario y contraseña filtradas en otros servicios. Si un usuario reutiliza credenciales, el atacante accede sin necesidad de hackear el sistema. Spoiler: no son hackers con capucha adivinando contraseñas una por una, son bots probando miles por


