

by drmunozcl
Share
Por drmunozcl
Compartir
Las vulnerabilidades no corregidas siguen siendo una de las vías más explotadas por atacantes. Durante la etapa de implementación del SDLC, aplicar actualizaciones y parches seguros determina si el despliegue protege o expone la organización. El reto real no es solo «parchar», sino hacerlo con verificación de origen, pruebas rigurosas, despliegues controlados y trazabilidad completa, sin romper el servicio ni introducir riesgos de cadena de suministro.
Actualizaciones y parches seguros en la implementación del SDLC
En implementación, la presión por entregar valor suele chocar con el tiempo que exigen los parches críticos. Sin gobierno y automatización, surgen fallas: paquetes comprometidos, incompatibilidades en producción, ventanas de indisponibilidad, o parches que no corrigen la vulnerabilidad. La salida es un proceso sistemático que prioriza por riesgo, verifica criptográficamente, prueba antes de producir y despliega de forma gradual con capacidad de reversión inmediata.
Proceso seguro paso a paso (recomendado)
Inventaria activos y genera SBOM
- Mantén un inventario vivo de servicios, librerías, imágenes base y sistemas operativos.
- Publica un SBOM por versión (SPDX o CycloneDX) para mapear dependencias y su exposición a CVE.
Prioriza por riesgo, no por orden de llegada
- Combina puntaje CVSS, explotación conocida (KEV), exposición del activo, criticidad del dato y facilidad de remediación.
- Define SLA de parcheo por severidad (p. ej., CRIT: 48 h; ALTA: 7 días).
Verifica el origen antes de actualizar
- Descarga desde repositorios confiables y habilita políticas de integridad (SLSA, firmas Sigstore/cosign, GPG, hashes SHA-256).
- Rechaza artefactos sin firma válida o con hash no coincidente.
Aísla cambios en una rama de parche
- Fija versiones y actualiza de forma controlada (semver). Regenera lockfiles.
- Ejecuta SCA para validar librerías y licencias; revisa notas de versión y breaking changes.
Prueba de seguridad y regresión automatizada
- Corre suites unitarias, integración, end-to-end y de rendimiento.
- Añade SAST/DAST/IAST, escaneo de contenedores e IaC. Bloquea el pipeline si falla cualquier control crítico.
Replica producción en staging
- Usa IaC para crear entornos equivalentes (red, TLS, secretos, datos sintéticos representativos).
- Valida migraciones reversibles y compatibilidad con dependencias externas.
Despliega de forma gradual y reversible
- Emplea canary, blue-green o feature flags. Define ventanas de mantenimiento cuando sea necesario.
- Mantén listo un plan de rollback atómico; nunca parchees directamente en caliente sin respaldo.
Observa y valida post-despliegue
- Monitorea métricas (latencia, errores), logs y trazas; establece umbrales y alertas.
- Verifica que el CVE objetivo quedó mitigado (pruebas de verificación, rescaneo y validación de firmas post-build).
Asegura datos y continuidad
- Realiza backups verificables antes de cambios; prueba la restauración periódicamente.
- Asegura que los cambios de esquema soportan downgrade.
Cierra con gobernanza y trazabilidad
- Registra ticket de cambio, aprobaciones, evidencia de pruebas y resultados del despliegue.
- Actualiza el SBOM, el historial de versiones y comunica a las áreas afectadas.
Buenas prácticas que reducen riesgo
- Automatiza el ciclo de parcheo: integra escaneo de vulnerabilidades, políticas de firma y gates en CI/CD.
- Minimiza la superficie: usa imágenes base pequeñas, elimina paquetes innecesarios y aplica hardening.
- Evita la deriva: rebuild de imágenes cuando haya parches base, en lugar de ejecutar comandos ad-hoc en producción.
- Protege credenciales: rota secretos tras parches críticos y usa gestores (Vault, KMS) con acceso mínimo necesario.
- Parcha el host y el orquestador: sistema operativo, hipervisores, Kubernetes y sus componentes (API Server, etcd, CNI).
- Gestiona endpoints con herramientas corporativas (WSUS/SCCM, Ansible, Puppet): aplica ventanas, reporta cumplimiento y excepciones.
- Alinea contratos y SaaS: valida que terceros mantengan parches al día y exige evidencia (attestations, reportes de seguridad).
Consideraciones específicas por entorno
| Entorno | Recomendaciones clave |
|---|---|
| Contenedores | Reconstruye imágenes desde Dockerfiles inmutables; firma y verifica con cosign; aplica PodSecurity y escaneo en admisión. |
| Kubernetes | Usa PodDisruptionBudget, surge upgrades en nodos y canary por Deployment; drena nodos antes de actualizarlos. |
| Bases de datos | Implementa réplicas y failover; prueba migraciones online y reversibles; coordina con aplicación. |
| Sistemas legacy | Aísla con segmentación/red, WAF/IPS virtual patching; plan de modernización paralelo. |
Errores comunes que debes evitar
- Actualizar directo en producción sin staging ni plan de rollback.
- Omitir la verificación criptográfica de artefactos.
- No fijar versiones ni regenerar lockfiles tras parches.
- Ignorar dependencias transitivas y su impacto.
- Saltar pruebas de rendimiento y compatibilidad de migraciones.
- Aplazar parches críticos por «no tocar lo que funciona».
Conclusión
Aplicar actualizaciones y parches seguros durante la implementación del SDLC exige método y disciplina: inventario y SBOM precisos, priorización por riesgo, verificación de origen, pruebas integrales, despliegues graduales, observabilidad y una gobernanza que deje rastro auditable. Con este flujo, reduces la ventana de exposición, evitas interrupciones innecesarias y elevas la resiliencia de tus servicios sin frenar la entrega continua.
MANTENTE INFORMADO
Suscríbete a nuestro newsletter gratuito.

La comunidad de desarrollo recibió una alerta importante: se han revelado vulnerabilidades críticas en ReactJs, específicamente en React Server Components (RSC), con potencial de denegación de servicio (DoS) y exposición de código fuente bajo ciertos escenarios. Para los equipos de TI y seguridad, el riesgo es tangible: interrupciones del servicio, filtración de lógica sensible y
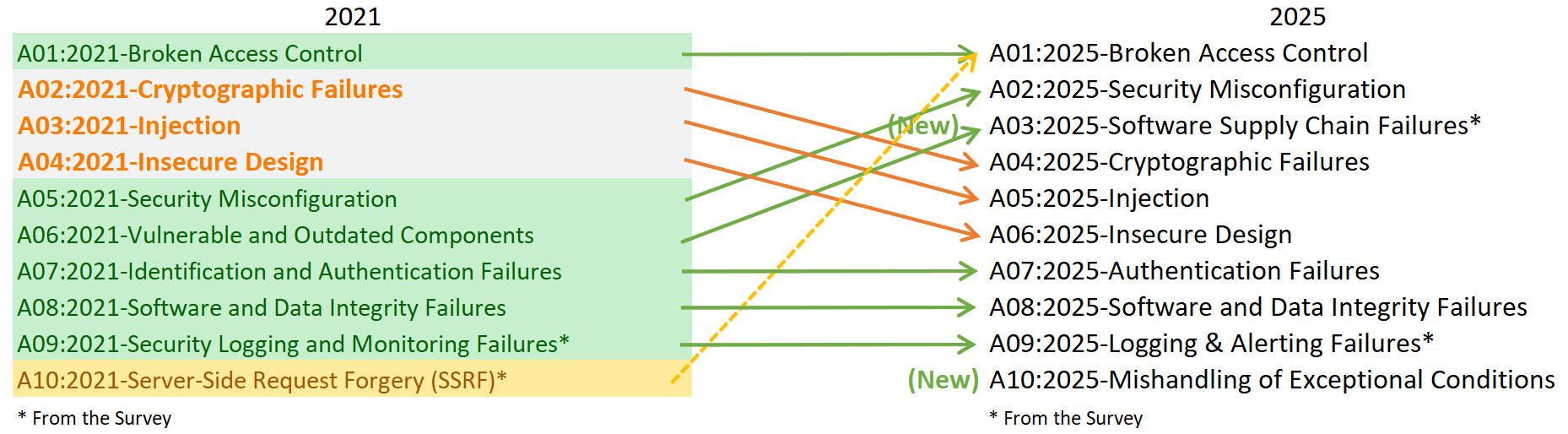
OWASP Top 10 2025 RC ya está disponible y marca el inicio de una fase clave para planificar estrategias de seguridad de aplicaciones de cara al próximo ciclo. Este release candidate ofrece una vista anticipada de cambios que influirán en prioridades de remediación, capacitación técnica y métricas de riesgo. Si lideras seguridad de aplicaciones o

La ciberseguridad no funciona con el modelo de «instalar y olvidar». En InfoProteccion defendemos la seguridad como proceso continuo porque las amenazas evolucionan, tu infraestructura cambia y el negocio no se detiene. Tratarla como un destino único crea una falsa sensación de control; tratarla como un ciclo permanente permite anticiparse, contener y recuperarse con rapidez.

La cultura de seguridad en equipos de desarrollo no es un eslogan, es el sistema operativo que protege tu software y tu negocio. Cuando el código sale rápido pero sin controles, las vulnerabilidades se cuelan, los costos de corrección se disparan y el equipo vive apagando incendios a deshoras. La buena noticia es que puedes


