

by drmunozcl
Share
Por drmunozcl
Compartir
Gestión de incidentes en SDLC: enfoque integral para desarrollo seguro
La gestión de incidentes en SDLC no es un apéndice operativo; es una disciplina estratégica que protege el valor del software desde la idea hasta la operación. Cuando los equipos relegan la respuesta a incidentes a producción, aumentan el tiempo de exposición, se multiplican los costos de corrección y se erosiona la confianza del cliente. Integrar prácticas de detección, respuesta y aprendizaje en cada fase del ciclo de vida reduce el riesgo, acelera la entrega y eleva la madurez de DevSecOps.
En Infoprotección te proponemos un marco que inserta controles, roles y métricas de respuesta a incidentes en el SDLC para anticipar fallas, contener rápidamente las brechas y convertir cada incidente en conocimiento accionable.
¿Por qué la gestión de incidentes en SDLC es crítica?
- Los ataques actuales explotan la cadena de suministro, configuraciones de IaC y pipelines CI/CD. Si no diseñamos para detectar y responder desde el inicio, el adversario aprovechará cada eslabón débil.
- La falta de telemetría útil y runbooks claros dispara la fatiga de alertas, retrasa la contención y aumenta el MTTR.
- Cumplimientos como ISO 27001, SOC 2 y regulaciones sectoriales exigen pruebas de capacidad de respuesta integradas al desarrollo y la operación.
El resultado de no integrar este enfoque se traduce en ventanas de exposición prolongadas, mayor pérdida de datos y paradas de servicio costosas. La solución: llevar la gestión de incidentes al corazón del SDLC.
Gestión de incidentes en SDLC: principios y responsabilidades
Principios clave:
- Detección temprana por diseño: instrumenta logging estructurado, trazas y métricas desde la fase de diseño.
- Automatización con criterio: orquesta respuestas repetibles con SOAR y policy-as-code, sin perder control humano en decisiones críticas.
- Aprendizaje continuo: postmortems sin culpa que alimentan backlog, estándares y runbooks.
- Visibilidad extremo a extremo: correlaciona eventos de aplicación, infraestructura y negocio en un SIEM con contexto de activos y amenazas.
Responsabilidades recomendadas:
- Product Owner: prioriza riesgos y acepta deuda de seguridad con criterios explícitos.
- Líder de AppSec: define políticas, herramientas y guía threat modeling.
- Equipo de Desarrollo: implementa controles, corrige vulnerabilidades y aporta telemetría útil.
- SRE/Plataforma: garantiza confiabilidad, hardening, observabilidad y guardrails de despliegue.
- SecOps/CSIRT: gestiona detección, triage, contención y coordinación de incidentes.
- Security Champions: actúan como enlace en cada squad.
Define severidades, SLAs por criticidad y canales de comunicación (internos/externos) antes del primer incidente.
Flujo recomendado de extremo a extremo
Planificación segura
- Realiza threat modeling (STRIDE, PASTA) y registra riesgos. Alinea Definition of Ready/Done con criterios de seguridad.
Telemetría desde el diseño
- Diseña logs estructurados, trazas distribuidas y métricas con IDs de correlación. Protege datos sensibles y define periodos de retención.
Codificación con controles
- Usa pre-commit hooks, SAST, escaneo de secretos y revisiones por pares con listas de verificación de seguridad.
- Construcción y cadena de suministro
- Endurece runners, genera SBOM, firma artefactos (Sigstore/cosign) y cumple SLSA. Escanea dependencias (SCA).
Pruebas de seguridad automatizadas
Preparación de entornos
- Aplica hardening, escanea IaC (tfsec/Checkov) y valida configuraciones de nube. Ensaya recuperación con copias verificadas.
Despliegue con guardrails
- Implementa canary/blue‑green, feature flags y políticas OPA/Kyverno. Monitorea errores y anomalías en tiempo real.
Detección y orquestación
- Centraliza señales en SIEM, reduce ruido con casos de uso de calidad y automatiza respuestas en SOAR para eventos repetibles.
Gestión del incidente
- Estandariza triage, contención, erradicación y recuperación. Mantén comunicación clara con partes interesadas.
Postmortem y mejora continua
- Analiza causa raíz, corrige deuda, actualiza runbooks, métricas y controles. Introduce pruebas de caos de seguridad y ejercicios tabletop.
Métricas, SLAs y reporting
- MTTA, MTTD, MTTR y tiempo de contención por severidad.
- Tasa de falsos positivos y cobertura de telemetría por servicio.
- Tiempo medio de remediación de vulnerabilidades (TTR) y ventana de exposición.
- Porcentaje de incidentes detectados internamente vs. reportados por clientes.
- Porcentaje de despliegues protegidos por políticas (policy-as-code) y firmas verificadas.
- SLAs sugeridos: Crítico ≤ 24 h, Alto ≤ 72 h, Medio ≤ 7 días, Bajo ≤ 30 días.
- Reporta tendencias por equipo y servicio para guiar inversiones y entrenamientos.
Buenas prácticas y anti‑patrones
Buenas prácticas:
- Designa Security Champions por squad y formaliza un RACI de incidentes.
- Versiona runbooks y enlázalos desde las alertas del SIEM/SOAR.
- Define SLOs de seguridad y error budgets específicos.
- Implementa zero‑trust, acceso JIT y MFA en pipelines y consolas.
- Prueba restauraciones con frecuencia; valida RTO/RPO.
- Mantén inventario de activos y dependencias con SBOM actualizado.
Anti‑patrones a evitar:
- Tratar los incidentes como problema exclusivo de producción.
- Depender solo del SIEM sin mejorar la calidad de la telemetría en la app.
- No priorizar por impacto en negocio y datos.
- Saltar postmortems o convertirlos en procesos punitivos.
- Silos entre Desarrollo, AppSec, SRE y SecOps.
Conclusión
La gestión de incidentes en SDLC exige un enfoque transversal: diseñar para detectar, automatizar lo repetible, practicar la respuesta y aprender de cada evento. Al integrar roles claros, telemetría útil, pipelines seguros y métricas accionables, los equipos reducen el riesgo y aceleran la entrega de software confiable. Este modelo convierte la respuesta a incidentes en una ventaja competitiva y en un pilar del desarrollo seguro de software.
MANTENTE INFORMADO
Suscríbete a nuestro newsletter gratuito.

La comunidad de desarrollo recibió una alerta importante: se han revelado vulnerabilidades críticas en ReactJs, específicamente en React Server Components (RSC), con potencial de denegación de servicio (DoS) y exposición de código fuente bajo ciertos escenarios. Para los equipos de TI y seguridad, el riesgo es tangible: interrupciones del servicio, filtración de lógica sensible y
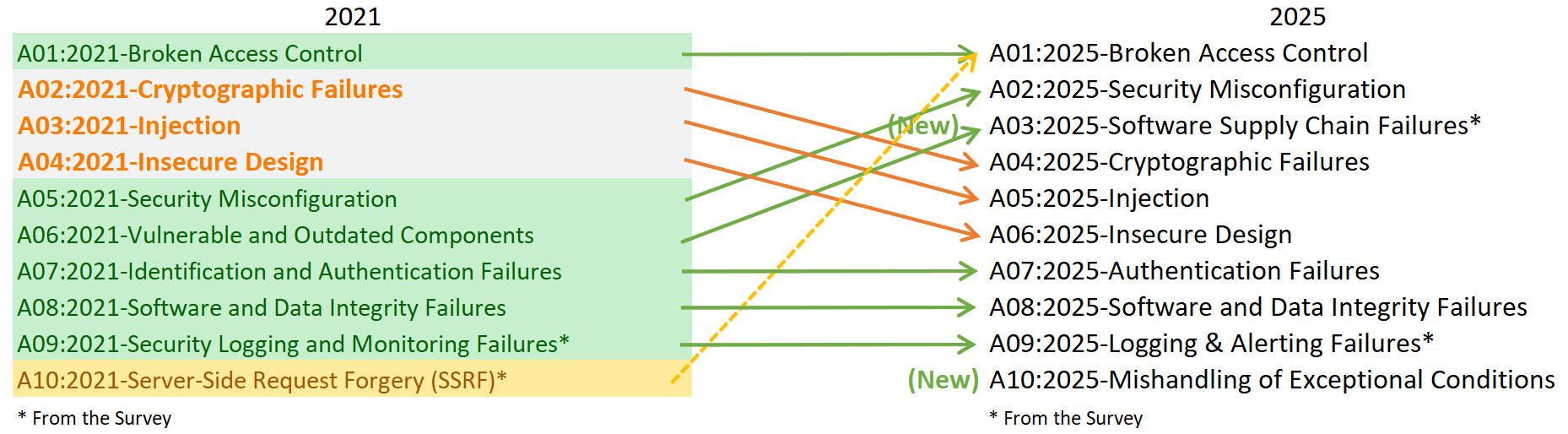
OWASP Top 10 2025 RC ya está disponible y marca el inicio de una fase clave para planificar estrategias de seguridad de aplicaciones de cara al próximo ciclo. Este release candidate ofrece una vista anticipada de cambios que influirán en prioridades de remediación, capacitación técnica y métricas de riesgo. Si lideras seguridad de aplicaciones o

La ciberseguridad no funciona con el modelo de «instalar y olvidar». En InfoProteccion defendemos la seguridad como proceso continuo porque las amenazas evolucionan, tu infraestructura cambia y el negocio no se detiene. Tratarla como un destino único crea una falsa sensación de control; tratarla como un ciclo permanente permite anticiparse, contener y recuperarse con rapidez.

La cultura de seguridad en equipos de desarrollo no es un eslogan, es el sistema operativo que protege tu software y tu negocio. Cuando el código sale rápido pero sin controles, las vulnerabilidades se cuelan, los costos de corrección se disparan y el equipo vive apagando incendios a deshoras. La buena noticia es que puedes


