

by drmunozcl
Share
Por drmunozcl
Compartir
El monitoreo de seguridad no puede ser un anexo al final del ciclo. Cuando los equipos lo postergan, aparecen puntos ciegos: pipelines alterados sin detección, secretos expuestos en repositorios, dependencias comprometidas que llegan a producción y tiempos de respuesta que se disparan. En un SDLC moderno, la única forma de reducir riesgo y mantener velocidad es diseñar el monitoreo desde la fase de planificación, con telemetría accionable y automatización.
Monitoreo de seguridad en el SDLC: arquitectura recomendada
Una arquitectura efectiva de monitoreo debe abarcar todo el flujo de desarrollo a operación:
- Recolección e instrumentación: instrumente aplicaciones y servicios con OpenTelemetry para métricas, logs y trazas. Integre fuentes de SCM, CI/CD, escáneres de seguridad, contenedores, orquestadores y nube.
- Normalización y enriquecimiento: unifique formatos con OCSF o ECS. Enriquezca con inventario de activos, etiquetas de entorno, identidades humanas y de servicio, SBOMs y contexto de amenazas.
- Almacenamiento y correlación: use un SIEM central (por ejemplo, Elastic, Splunk o Microsoft Sentinel) y un lago de datos para históricos. Procese eventos en streaming con Kafka o servicios nativos de nube.
- Detección como código: gestione reglas en repositorios versionados con pruebas unitarias de detecciones usando plantillas Sigma, Kusto u otras. Aplique revisiones de código y despliegue continuo de reglas.
- Respuesta y orquestación: active playbooks en una plataforma SOAR, integre ChatOps, ITSM y controladores de admisión para bloquear automáticamente.
- Protección preventiva y atestación: firme artefactos con Sigstore Cosign, genere y verifique attestations in-toto, adopte SLSA para trazabilidad. Aplique políticas como código con OPA y verificación en Admission Controllers.
- Gobierno y métricas: defina SLOs de seguridad, SLAs de remediación y un registro de riesgos conectado con el backlog del producto.
Fuentes de telemetría más relevantes por fase del SDLC
Mapee fuentes a cada etapa para cerrar brechas de visibilidad:
- Planificación: historias con requisitos de seguridad asociados a la generación de logs.
- Codificación: Registrar eventos de repositorios Git, protección de ramas, revisiones, escaneo de secretos con Gitleaks, SAST con Semgrep u otra herramienta.
- Compilación y empaquetado: logs de CI/CD (GitHub Actions, GitLab CI, Jenkins), escaneo de dependencias y SBOM con Syft y Trivy o Grype, firmas de artefactos con Cosign. Telemetría: quien ejecuta, qué cambia, atestaciones y resultados de escaneo.
- Pruebas: DAST con OWASP ZAP o Burp automatizado; pruebas de fuzzing; resultados de seguridad en integración. Telemetría: issues reproducibles, endpoints afectados, tasa de falsos positivos.
- Despliegue: registros del orquestador (Kubernetes audit logs), admission webhooks, cambios de configuración, verificación de imágenes en el registro. Telemetría: quién despliega, qué política validó, qué se bloqueó.
- Operación: logs de aplicaciones (Loki o Elastic), métricas de Prometheus, trazas, EDR del host, Falco para kernel y contenedores, CloudTrail o equivalentes en Azure y GCP. Telemetría: anomalías, picos de error, llamadas sospechosas, exfiltración potencial.
Métricas, KPIs y umbrales de alerta
Defina objetivos cuantificables para sostener el programa:
- MTTD y MTTR de incidentes de CI/CD: objetivo inicial menor a 15 minutos y menor a 60 minutos respectivamente.
- Porcentaje de pipelines con atestación válida y verificación de firma: objetivo mayor al 95%.
- Cobertura de telemetría crítica por servicio: logs, métricas y trazas activas mayor al 90%.
- SLA de vulnerabilidades: críticas corregidas en menos de 7 días; altas en menos de 14 días.
- Tasa de pushes con secretos bloqueados por pre-commit o servidor: tendencia descendente semanal.
- Ratio de falsos positivos en detecciones clave: menor al 10% para evitar fatiga de alertas.
Reglas de detección prioritarias
- Commit con credenciales o tokens en repositorios internos o externos.
- Modificación de políticas de rama sin aprobación del propietario del repositorio.
- Ejecución de pipelines firmados por identidades no esperadas o desde ubicaciones atípicas.
- Uso de dependencias retiradas o paquetes typosquatting en build.
- Imagen de contenedor sin firma válida o con atestación ausente desplegada en clúster.
- Escalada de privilegios en Kubernetes, creación de ServiceAccount cluster-admin o uso de tokens desde pods no autorizados.
- Extracción masiva de secretos desde el gestor o acceso fuera de horario normal.
- Tráfico de salida anómalo desde servicios que manejan datos sensibles hacia dominios no categorizados.
- Cambios de infraestructura que abren puertos o desactivan cifrado en bases de datos gestionadas.
- Fallos repetidos en autenticación de cuentas de servicio o rotación inesperada de claves.
Automatización del monitoreo de seguridad
- Bloqueo temprano: valide políticas con OPA y Conftest en PRs y pipelines. Si falla, detenga el merge y notifique con detalles reproducibles.
- Gating en despliegue: exija SBOM y firma verificable; si faltan, el Admission Controller rechaza el recurso.
- SOAR y runbooks: para cada alerta prioritaria, defina un playbook con enriquecimiento, asignación a equipo responsable, contención y verificación post-mortem.
- ChatOps: envíe resúmenes a canales de ingeniería con enlaces a tableros, evidencias y botones para ejecutar acciones seguras.
- Validación continua: ejecute simulaciones de ataque a la cadena de suministro y purple teaming para probar reglas y playbooks.
Lista de implementación paso a paso
- Defina amenazas prioritarias con threat modeling de la cadena de suministro y servicios críticos.
- Acepte estándares de datos: adopte OCSF o ECS y un esquema común de identidades y activos.
- Instrumente aplicaciones y servicios con OpenTelemetry; habilite logs estructurados.
- Integre SCM y CI/CD: eventos de repos, pipelines, artefactos, aprobaciones y roles.
- Active escáneres: SAST, DAST, IaC, dependencias y secretos con salida en formato estándar y severidad consistente.
- Genere SBOMs por build y firme artefactos con Cosign; emita attestations in-toto.
- Centralice en su SIEM; configure ingesta, normalización, enriquecimiento y retención por criticidad.
- Escriba detecciones como código con pruebas; despliegue en ramas protegidas con revisión de seguridad.
- Defina KPIs, SLOs y dashboards de seguridad visibles para ingeniería y liderazgo.
- Diseñe playbooks en SOAR, integre ITSM, ChatOps y conectores de contención.
- Aplique controles preventivos: OPA, admission policies, verificación de firmas y bloqueo de secretos en commits.
- Ejecute ejercicios trimestrales de validación y ajuste reglas, umbrales y playbooks según hallazgos.
Conclusión
El monitoreo de seguridad, integrado a cada fase del SDLC, reduce tiempos de detección, evita despliegues inseguros y aporta trazabilidad completa de cambios. Al unificar telemetría, detecciones como código y automatización, su equipo gana velocidad con control, mejora la postura frente a la cadena de suministro y entrega software resiliente sin fricción innecesaria. La clave es diseñar la arquitectura, medir continuamente y cerrar el ciclo con respuesta y mejora continua.
MANTENTE INFORMADO
Suscríbete a nuestro newsletter gratuito.

La comunidad de desarrollo recibió una alerta importante: se han revelado vulnerabilidades críticas en ReactJs, específicamente en React Server Components (RSC), con potencial de denegación de servicio (DoS) y exposición de código fuente bajo ciertos escenarios. Para los equipos de TI y seguridad, el riesgo es tangible: interrupciones del servicio, filtración de lógica sensible y
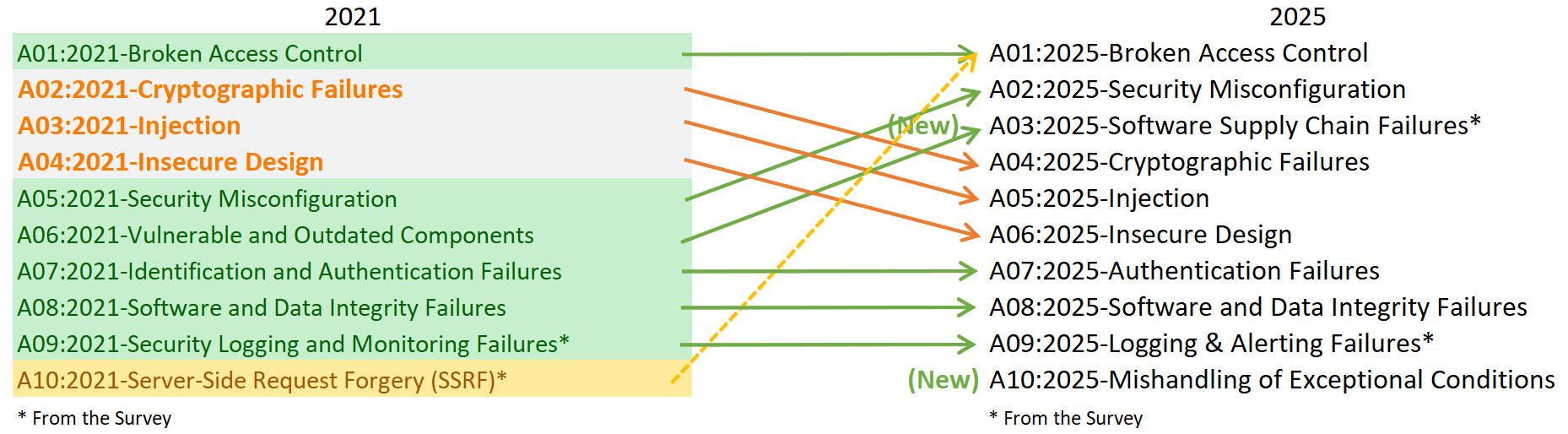
OWASP Top 10 2025 RC ya está disponible y marca el inicio de una fase clave para planificar estrategias de seguridad de aplicaciones de cara al próximo ciclo. Este release candidate ofrece una vista anticipada de cambios que influirán en prioridades de remediación, capacitación técnica y métricas de riesgo. Si lideras seguridad de aplicaciones o

La ciberseguridad no funciona con el modelo de «instalar y olvidar». En InfoProteccion defendemos la seguridad como proceso continuo porque las amenazas evolucionan, tu infraestructura cambia y el negocio no se detiene. Tratarla como un destino único crea una falsa sensación de control; tratarla como un ciclo permanente permite anticiparse, contener y recuperarse con rapidez.

La cultura de seguridad en equipos de desarrollo no es un eslogan, es el sistema operativo que protege tu software y tu negocio. Cuando el código sale rápido pero sin controles, las vulnerabilidades se cuelan, los costos de corrección se disparan y el equipo vive apagando incendios a deshoras. La buena noticia es que puedes


