

by drmunozcl
Share
Por drmunozcl
Compartir
En un SDLC seguro, la etapa de pruebas ya no puede limitarse a casos de uso felices ni a validaciones manuales puntuales. Las amenazas evolucionan más rápido que los ciclos de release, el tiempo de explotación de CVE se reduce y los entornos modernos distribuidos multiplican la superficie de ataque. El resultado es predecible: vulnerabilidades que llegan a producción, deuda técnica de seguridad y brechas costosas. Para cortar ese ciclo, integre el escaneo de vulnerabilidades y fuzzing desde la etapa de pruebas, con automatización y métricas que permitan tomar decisiones informadas.
El escaneo de vulnerabilidades y fuzzing detecta debilidades conocidas y fallos inesperados antes de que los usuarios las sufran. Hecho bien, este enfoque reduce el MTTR de seguridad, fortalece los controles de calidad y habilita releases confiables sin frenar la entrega continua.
¿Qué es el escaneo de vulnerabilidades y fuzzing en el SDLC?
- Escaneo de vulnerabilidades: conjunto de pruebas automatizadas que identifican debilidades conocidas en código, dependencias, contenedores, infraestructura y servicios expuestos. Incluye SAST, SCA, DAST e IAST.
- Fuzzing: generación de entradas semi-aleatorias o guiadas por cobertura para provocar fallos en parsers, APIs, binarios y servicios. Encuentra errores de validación, desbordamientos, condiciones de carrera, null dereferences y rutas lógicas poco exploradas.
Comparación rápida:
| Práctica | Enfoque | Cuándo usar | Beneficio clave |
|---|---|---|---|
| Escaneo de vulnerabilidades | Firma, heurística y reglas | En cada cambio y release | Descubre debilidades conocidas y configuraciones riesgosas |
| Fuzzing | Mutación y cobertura | En parsers, APIs y binarios críticos | Encuentra fallos desconocidos y casos límite |
Ambas prácticas se complementan: el escaneo reduce exposición conocida y el fuzzing descubre lo que no ve el catálogo de CVE ni las reglas estáticas.
Integración del escaneo de vulnerabilidades y fuzzing en la etapa de pruebas del desarrollo seguro
Para maximizar valor, integre estas pruebas en su pipeline CI/CD y en entornos realistas.
-
Defina el alcance y priorice activos
- Identifique componentes críticos: parsers, endpoints expuestos, servicios con datos sensibles y librerías nativas.
- Mapee dependencias (SBOM) y servicios externos. Priorice por impacto y exposición.
-
Prepare entornos de prueba representativos
- Use entornos efímeros que reflejen configuración de producción, incluyendo secretos gestionados y políticas de red.
- Trace rutas de ataque posibles desde el borde hasta servicios internos.
-
Automatice el escaneo en el pipeline
- SCA: escanee dependencias y contenedores en cada commit y PR. Use políticas para bloquear CVE de criticidad alta.
- SAST/IAST: ejecute análisis en cada build. Conserve reglas personalizadas para patrones de su código.
- DAST: lance pruebas contra entornos de staging con datos sintéticos. Programe escaneos rápidos en PR y completos por release.
-
Orqueste fuzzing con disciplina de ingeniería
- Modele objetivos de fuzzing (APIs REST, binarios, parsers de archivos). Cree harnesses y defina oráculos de fallo.
- Alimente corpus inicial con tráfico real anonimizado y ejemplos de formatos válidos.
- Active sanitizadores e instrumentación de cobertura (ASan, UBSan, coverage-guided). Escale ejecuciones en workers.
-
Gestione hallazgos con flujo claro
- Deduplice por stack hash y por endpoint. Priorice por explotabilidad y datos afectados.
- Vincule hallazgos a historias técnicas y políticas de remediación con SLAs por severidad.
-
Remedie y revalide sin fricción
- Parchee dependencias, aplique hardening y agregue tests de regresión que reproduzcan el crash o la PoC.
- Reejecute escaneos y fuzzers para validar la corrección.
-
Telemetría y criterios de salida
- Defina umbrales de cobertura, tasa de crashes únicos y cero hallazgos críticos para aprobar releases.
- Consolide métricas en dashboards para equipos de desarrollo y seguridad.
-
Ritmo operativo
- Escaneo SCA/SAST en cada commit; DAST por PR y completo semanal; fuzzing continuo en nightly y campañas extendidas para módulos críticos.
Mejores prácticas para el escaneo de vulnerabilidades y fuzzing
- Trate seguridad como calidad: convierta hallazgos en pruebas de regresión automatizadas.
- Mantenga SBOM actualizado y suscríbase a feeds de CVE para rastrear impacto.
- Cree perfiles de escaneo con distintos niveles de profundidad para no penalizar el time-to-merge.
- Use datos y tokens sintéticos; no exponga secretos reales durante las pruebas.
- Para fuzzing de APIs, defina contratos precisos (OpenAPI/JSON Schema) y valide oráculos con aserciones claras.
- Active sanitizadores de memoria y condiciones de carrera en C/C++; en JVM y .NET, combine fuzzing con validación de invariantes.
- Mida cobertura relevante: rutas de validación, parsers y serializadores; no se limite a líneas ejecutadas.
- Integre revisión humana para hallazgos críticos o complejos; automatice el resto.
- Aisle infraestructura de fuzzing para evitar denegaciones de servicio accidentales y limite tasas de request.
Cobertura, métricas y criterios de salida
- Cobertura guiada por riesgo
- Funcional: endpoints y operaciones críticas alcanzadas ≥ 90%.
- Sintáctica: variaciones de formato procesadas (válidas e inválidas).
- Semántica: reglas de negocio adversas ejercitadas.
- Calidad del fuzzing
- Crashes únicos por semana (stack hash) y tiempo al primer crash.
- Tasa de expansión del corpus y saturación de nuevas rutas.
- Eficacia del escaneo
- MTTR de vulnerabilidades por severidad.
- Falsos positivos bajo umbral definido (<10% en SAST con reglas sintonizadas).
- Porcentaje de componentes con CVE críticas resueltas antes del release.
- Criterios de salida
- Cero hallazgos críticos abiertos.
- Reducción sostenida de crashes únicos a tendencia estable.
- Cobertura mínima alcanzada en módulos de alto riesgo.
Herramientas y enfoques recomendados
- Escaneo de vulnerabilidades
- Dependencias y contenedores: Trivy, Grype, Snyk, Anchore, Dependabot.
- Código y aplicaciones: SAST/IAST integrados en GitLab/GitHub, SonarQube, Semgrep.
- Superficie expuesta y configuración: OpenVAS/Greenbone, Nessus; análisis de IaC con Checkov, tfsec.
- DAST para web y APIs: OWASP ZAP, Burp Suite, scanners con soporte OpenAPI.
- Fuzzing
- C/C++: AFL++, libFuzzer, Honggfuzz con ASan/UBSan/TSan.
- JVM y .NET: Jazzer, JQF, SharpFuzz.
- APIs: RESTler, boofuzz; combine con contratos OpenAPI.
- Orquestación: OSS-Fuzz y ClusterFuzzLite para CI; infraestructura propia con workers y colas de tareas.
Seleccione herramientas según lenguaje, stack y presupuesto, pero mantenga la disciplina: harnesses bien diseñados, corpus versionado y retroalimentación a desarrollo.
Errores comunes a evitar
- Confiar solo en escaneo superficial y omitir fuzzing en parsers y endpoints críticos.
- Ejecutar DAST sin autenticación ni estados de sesión, perdiendo rutas relevantes.
- Ignorar configuración de tiempo y recursos; fuzzers que corren poco no exploran.
- No priorizar por impacto; backlog infinito sin resolución.
- Falta de oráculos claros en fuzzing, generando ruido y falsos positivos.
- No convertir hallazgos en pruebas de regresión; reincidencia de vulnerabilidades.
Conclusión
El escaneo de vulnerabilidades y fuzzing, integrados en la etapa de pruebas del SDLC seguro, elevan la barra de calidad y reducen riesgo real. Automatice donde tenga sentido, mida con métricas accionables y exija criterios de salida estrictos. Así, su pipeline entrega software más robusto sin frenar la cadencia de releases.
MANTENTE INFORMADO
Suscríbete a nuestro newsletter gratuito.

La comunidad de desarrollo recibió una alerta importante: se han revelado vulnerabilidades críticas en ReactJs, específicamente en React Server Components (RSC), con potencial de denegación de servicio (DoS) y exposición de código fuente bajo ciertos escenarios. Para los equipos de TI y seguridad, el riesgo es tangible: interrupciones del servicio, filtración de lógica sensible y
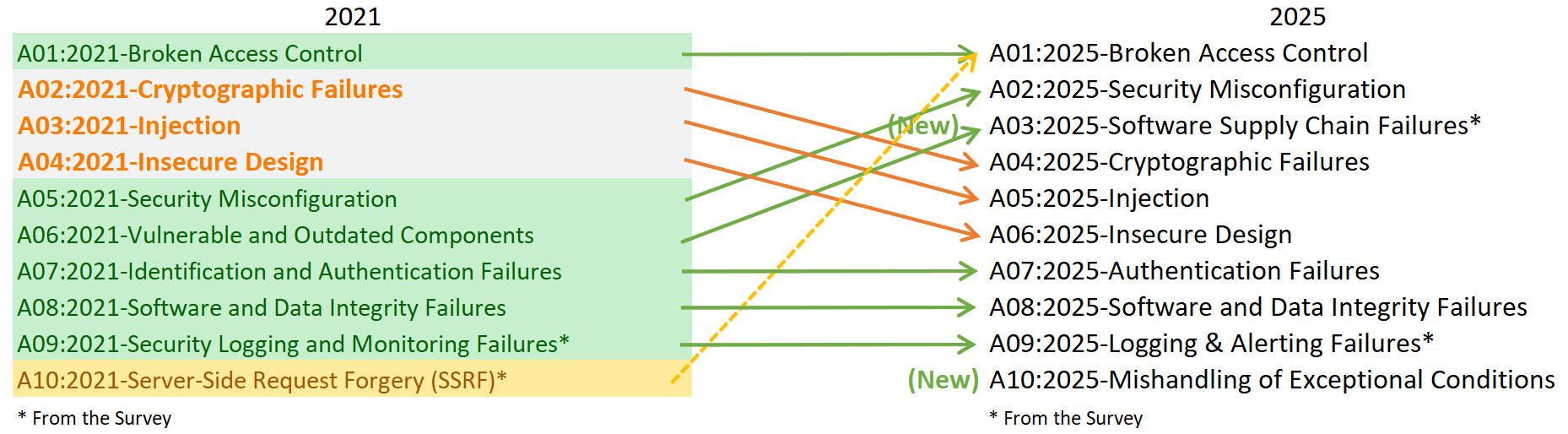
OWASP Top 10 2025 RC ya está disponible y marca el inicio de una fase clave para planificar estrategias de seguridad de aplicaciones de cara al próximo ciclo. Este release candidate ofrece una vista anticipada de cambios que influirán en prioridades de remediación, capacitación técnica y métricas de riesgo. Si lideras seguridad de aplicaciones o

La ciberseguridad no funciona con el modelo de «instalar y olvidar». En InfoProteccion defendemos la seguridad como proceso continuo porque las amenazas evolucionan, tu infraestructura cambia y el negocio no se detiene. Tratarla como un destino único crea una falsa sensación de control; tratarla como un ciclo permanente permite anticiparse, contener y recuperarse con rapidez.

La cultura de seguridad en equipos de desarrollo no es un eslogan, es el sistema operativo que protege tu software y tu negocio. Cuando el código sale rápido pero sin controles, las vulnerabilidades se cuelan, los costos de corrección se disparan y el equipo vive apagando incendios a deshoras. La buena noticia es que puedes


