

by drmunozcl
Share
Por drmunozcl
Compartir
El Fuzzing es una técnica de prueba automatizada que envía entradas aleatorias, mutadas o generadas a un objetivo para provocar fallos y descubrir vulnerabilidades. En ciberseguridad, el Fuzzing permite detectar errores de memoria, validación deficiente de datos y estados inesperados en binarios, parsers, protocolos, APIs y firmware. Su eficacia radica en la ejecución masiva y guiada por cobertura, lo que revela defectos que escapan a pruebas tradicionales.
Cómo funciona el Fuzzing
A grandes rasgos, el flujo de trabajo del Fuzzing es el siguiente:
- Definir el objetivo: binario, biblioteca, parser, protocolo o endpoint HTTP.
- Preparar un harness y un corpus de semillas representativo; instrumentar con cobertura y sanitizadores como ASan y UBSan.
- Ejecutar el fuzzer en bucle; muta o genera casos de prueba y prioriza rutas nuevas mediante cobertura.
- Monitorizar resultados: registrar bloqueos, timeouts y aserciones; reproducir y minimizar casos que fallan.
- Triaged y corrección: deduplicar por backtrace y cobertura, priorizar impactos y automatizar en CI CD para evitar regresiones.
Tipos de Fuzzing y herramientas
- Basado en mutación: altera entradas reales para explorar variaciones rápidamente. Ejemplos: AFL y AFL++, honggfuzz.
- Basado en generación: crea entradas con conocimiento del formato o protocolo, útil para gramáticas complejas.
- Guiado por cobertura: instrumenta el código y favorece casos que abren nuevas rutas. Ejemplos: libFuzzer, AFL++.
- Ecosistema: OSS-Fuzz ofrece infraestructura en la nube para proyectos open source y acelera la detección de fallos críticos.
Métricas y buenas prácticas de Fuzzing
- Cobertura alcanzada y funciones no ejercitadas.
- Crashes únicos y calidad del corpus minimizado.
- Rendimiento del fuzzer en ejecuciones por segundo y estabilidad.
- Integración en CI CD, sandboxing y limitación de recursos.
- Harnesses pequeños y deterministas; registro de semillas que reproducen fallos.
Conclusión
El Fuzzing aporta una defensa proactiva al encontrar vulnerabilidades desconocidas con alta probabilidad de explotación. Integrarlo en el ciclo de desarrollo seguro complementa SAST y DAST, reduce deuda técnica y eleva la resiliencia de software y servicios.
Relacionado
MANTENTE INFORMADO
Suscríbete a nuestro newsletter gratuito.

La inteligencia artificial (IA) está transformando la forma en que las organizaciones operan, toman decisiones y ofrecen servicios. Desde asistentes virtuales hasta sistemas de análisis predictivo, el uso de IA crece rápidamente en empresas de todos los sectores. Sin embargo, junto con los beneficios también surgen nuevos riesgos: sesgos en los algoritmos, uso indebido de
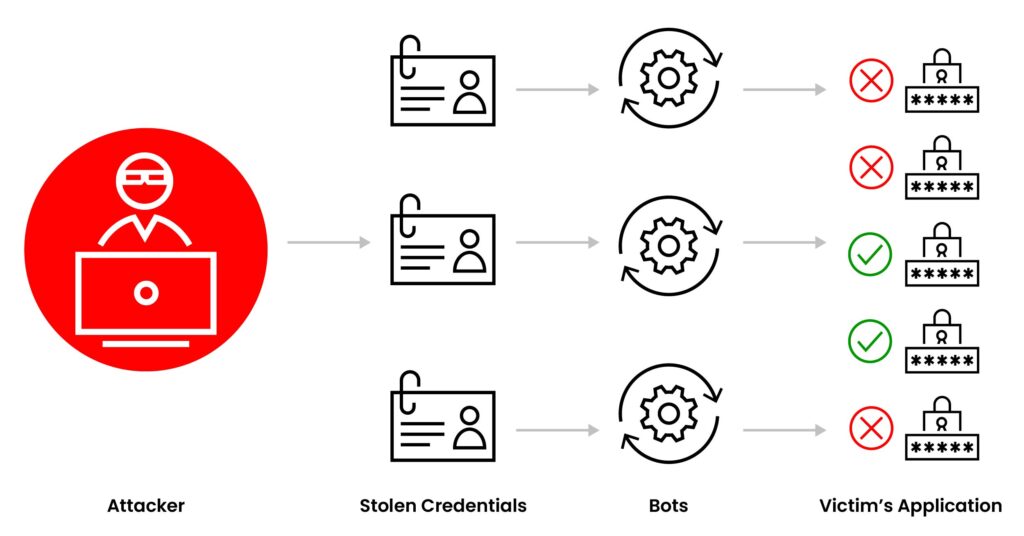
Te preguntas «¿Qué es Credential Stuffing?» Es un ataque automatizado donde delincuentes prueban, a gran escala, combinaciones de usuario y contraseña filtradas en otros servicios. Si un usuario reutiliza credenciales, el atacante accede sin necesidad de hackear el sistema. Spoiler: no son hackers con capucha adivinando contraseñas una por una, son bots probando miles por
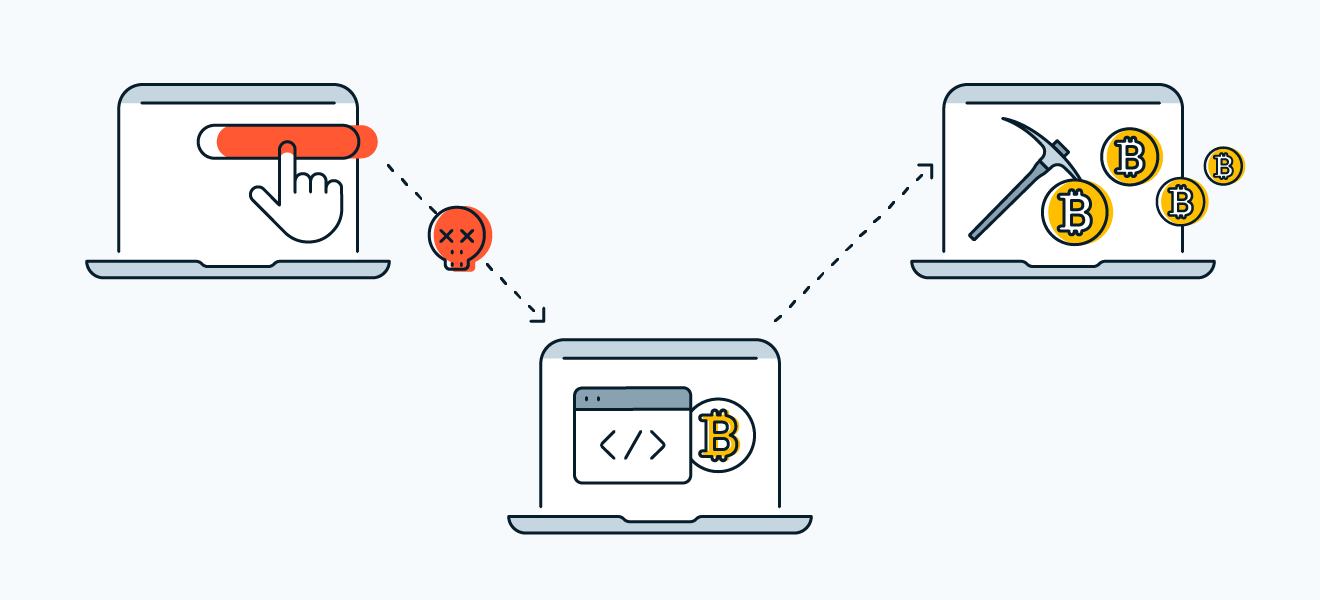
Si te preguntas qué es criptojacking, es el uso no autorizado de los recursos de cómputo (CPU/GPU, energía y red) de tus equipos o servidores para minar criptomonedas, generalmente Monero, por parte de atacantes. No roban datos directamente, pero exprimen tu infraestructura, encarecen la nube y reducen el rendimiento; si tu CPU suena como turbina

Si tu estrategia de seguridad se basa en que nadie entenderá tu código o en mantener en secreto cómo funciona tu sistema, estás compitiendo contra el tiempo. Un empleado que cambia de equipo, un repositorio mal configurado o una filtración en un proveedor pueden exponer tus detalles técnicos. Cuando eso ocurre, el ataque deja de


